Collection API
• Collection API提供“集合”“收集”的功能
• Collection API包含一系列的接口和类
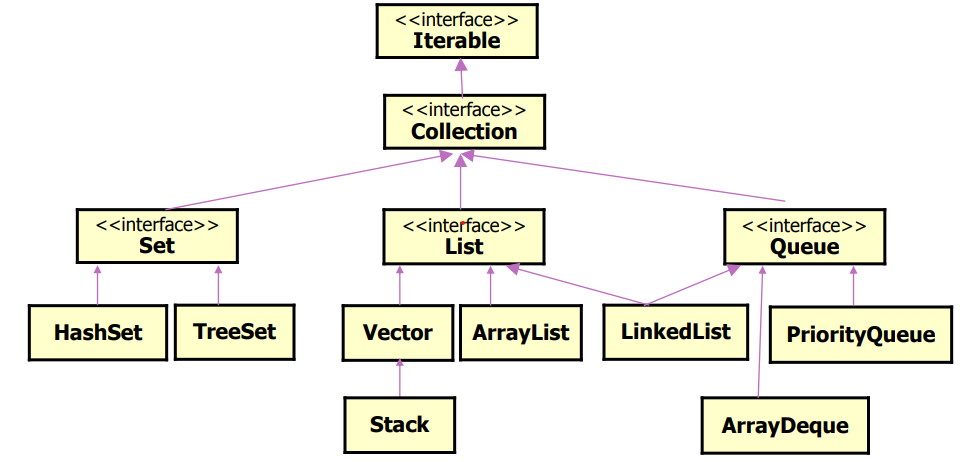
Collection接口:有两个子接口
• List: (Collection的子接口)记录元素的保存顺序,且允许有重复元素
• Set: (Collection的子接口)不记录元素的保存顺序,且不允许有重复元素
Map接口,即映射
• 键-值对(key-value pair)的集合
Collection接口
主要的方法:
| 方法 :返回类型 | |
|---|---|
| +add(element : Object) : boolean | 添加元素 |
| +remove(element : Object) : boolean | 删除元素 |
| +size() : int | 集合中元素的个数 |
| +isEmpty() : boolean | 集合是否为空 |
| +contains(element : Object) : boolean | 是否包含某个元素 |
| +iterator() : Iterator | 迭代器 |
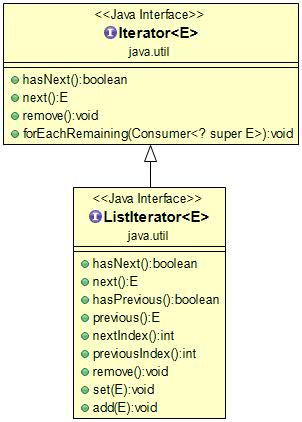
迭代器(Iterator)
迭代器不是一个集合,它是一种用于访问集合的方法,可用于迭代 ArrayList 和 HashSet 等集合。
-
Iterator 是 Java 迭代器最简单的实现,ListIterator 是 Collection API 中的接口, 它扩展了 Iterator 接口。
-
迭代器 it 的两个基本操作是 next 、hasNext 和 remove。
-
调用 it.next() 会返回迭代器的下一个元素,并且更新迭代器的状态。
-
调用 it.hasNext() 用于检测集合中是否还有元素。
-
调用 it.remove() 将迭代器返回的元素删除。
-
增强的for语句
在JDK1.5以后,增强的for语句(enhanced for)或叫for-each
for( Element e : list ) doSomething(e);
• for (Photo photo : album){
• System.out.println( photo.toString() );
• }
编译器生成了Iterator的while(hasNext()) {….next() }
Collection API 层次结构
List 线性表
线性表是最基本、最简单、也是最常用的一种数据结构。线性表(linear list)是数据结构的一种,一个线性表是n个具有相同特性的数据元素的有限序列。
线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的(注意,这句话只适用大部分线性表,而不是全部。比如,循环链表逻辑层次上也是一种线性表(存储层次上属于链式存储,但是把最后一个数据元素的尾指针指向了首位结点)。
特征
1.集合中必存在唯一的一个“第一元素”。
2.集合中必存在唯一的一个 “最后元素” 。
3.除最后一个元素之外,均有唯一的后继(后件)。
4.除第一个元素之外,均有唯一的前驱(前件)。
线性表主要由顺序表示ArrayList或链式表示LinkedList。
顺序表示指的是用一组地址连续的存储单元依次存储线性表的数据元素,称为线性表的顺序存储结构或顺序映像(sequential mapping)。它以“物理位置相邻”来表示线性表中数据元素间的逻辑关系,可随机存取表中任一元素。
链式表示指的是用一组任意的存储单元存储线性表中的数据元素,称为线性表的链式存储结构。它的存储单元可以是连续的,也可以是不连续的。在表示数据元素之间的逻辑关系时,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置),这两部分信息组成数据元素的存储映像,称为结点(node)。它包括两个域;存储数据元素信息的域称为数据域;存储直接后继存储位置的域称为指针域。指针域中存储的信息称为指针或链。
实现
主要的实现类是 ArrayList. LinkedList, 以及早期的Vector
• E get(int index);
• E set(int index, E element);
• void add(int index, E element);
• E remove(int index);
• int indexOf(Object o);
Stack 栈
栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈(push),它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈(pop),它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
• 遵循“后进先出”(Last In First Out, LIFO)原则
• 包含三个方法
public Object push(Object item):将指定对象压入栈中。
Public Object pop():将 栈最上面的元素从栈中取出,并返回这个对象。
public boolean empty():判断栈中没有对象元素。
队列Queue
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
队列的数据元素又称为队列元素。在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出(FIFO—first in first out)线性表。
顺序队列
建立顺序队列结构必须为其静态分配或动态申请一片连续的存储空间,并设置两个指针进行管理。一个是队头指针front,它指向队头元素;另一个是队尾指针rear,它指向下一个入队元素的存储位置。
每次在队尾插入一个元素是,rear增1;每次在队头删除一个元素时,front增1。随着插入和删除操作的进行,队列元素的个数不断变化,队列所占的存储空间也在为队列结构所分配的连续空间中移动。当front=rear时,队列中没有任何元素,称为空队列。当rear增加到指向分配的连续空间之外时,队列无法再插入新元素,但这时往往还有大量可用空间未被占用,这些空间是已经出队的队列元素曾经占用过得存储单元。
顺序队列中的溢出现象:
(1) "下溢"现象:当队列为空时,做出队运算产生的溢出现象。“下溢”是正常现象,常用作程序控制转移的条件。
(2)"真上溢"现象:当队列满时,做进栈运算产生空间溢出的现象。“真上溢”是一种出错状态,应设法避免。
(3)"假上溢"现象:由于入队和出队操作中,头尾指针只增加不减小,致使被删元素的空间永远无法重新利用。当队列中实际的元素个数远远小于向量空间的规模时,也可能由于尾指针已超越向量空间的上界而不能做入队操作。该现象称为"假上溢"现象。
循环队列
在实际使用队列时,为了使队列空间能重复使用,往往对队列的使用方法稍加改进:无论插入或删除,一旦rear指针增1或front指针增1 时超出了所分配的队列空间,就让它指向这片连续空间的起始位置。自己真从MaxSize-1增1变到0,可用取余运算rear%MaxSize和front%MaxSize来实现。这实际上是把队列空间想象成一个环形空间,环形空间中的存储单元循环使用,用这种方法管理的队列也就称为循环队列。除了一些简单应用之外,真正实用的队列是循环队列。
在循环队列中,当队列为空时,有front=rear,而当所有队列空间全占满时,也有front=rear。为了区别这两种情况,规定循环队列最多只能有MaxSize-1个队列元素,当循环队列中只剩下一个空存储单元时,队列就已经满了。因此,队列判空的条件时front=rear,而队列判满的条件时front=(rear+1)%MaxSize。
队列的数组实现
队列可以用数组Q[1…m]来存储,数组的上界m即是队列所容许的最大容量。在队列的运算中需设两个指针:head,队头指针,指向实际队头元素;tail,队尾指针,指向实际队尾元素的下一个位置。一般情况下,两个指针的初值设为0,这时队列为空,没有元素。数组定义Q[1…10]。Q(i) i=3,4,5,6,7,8。头指针head=2,尾指针tail=8。队列中拥有的元素个数为:L=tail-head。现要让排头的元素出队,则需将头指针加1。即head=head+1这时头指针向上移动一个位置,指向Q(3),表示Q(3)已出队。如果想让一个新元素入队,则需尾指针向上移动一个位置。即tail=tail+1这时Q(9)入队。当队尾已经处理在最上面时,即tail=10,如果还要执行入队操作,则要发生"上溢",但实际上队列中还有三个空位置,所以这种溢出称为"假溢出"。
克服假溢出的方法有两种。一种是将队列中的所有元素均向低地址区移动,显然这种方法是很浪费时间的;另一种方法是将数组存储区看成是一个首尾相接的环形区域。当存放到n地址后,下一个地址就"翻转"为1。在结构上采用这种技巧来存储的队列称为循环队列。
队列和栈一样只允许在断点处插入和删除元素。
循环队的入队算法如下:
1、tail=tail+1;
2、若tail=n+1,则tail=1;
3、若head=tail,即尾指针与头指针重合了,表示元素已装满队列,则作上溢出错处理;
4、否则,Q(tail)=X,结束(X为新入出元素)。
队列和栈一样,有着非常广泛的应用。
注意:(1)有时候队列中还会设置表头结点,就是在队头的前面还有一个结点,这个结点的数据域为空,但是指针域指向队头元素。
(2)另外,上面的计算还可以利用下面给出的公式cq.rear=(cq.front+1)/max;
当有表头结点时,公式变为cq.rear=(cq.front+1)/(max+1)。
重要的实现是LinkedList类
| 可抛出异常的 | 返回元素的 | |
|---|---|---|
| Insert(插入) | add(e) | offer(e) |
| Remove(移除) | remove() | poll() |
| Examine(检查) | element() | peek() |
LinkedList
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(stack),这样看来,linkedList简直就是无敌的,当你需要使用栈或者队列时,可以考虑用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(只是一个接口的名字)。关于栈或队列,现在首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)更好的性能。
几个早期的类或接口
• Vector, 现多用 ArrayList
相当于动态数组(比JDK1.0中的 ArrayList好), elementAt,
• Stack, 现多用 LinkedList
Stack是Vector的子类, push, pop, peek
• Hashtable, 现多用 HashMap
Hashtable实现Map接口, 参见Properties类
• Enumeration, 现多用Iterator
Enumeration用另一种方式实现Iterator的功能
如Vector可以得到枚举器
Enumeration
while(e.hasMoreElements()) doSomething(e.nextElement())
Set 集
两个重要的实现 HashSet及TreeSet
其中TreeSet的底层是用TreeMap来实现的
• Set中对象不重复,即:
hashCode()不等
如果hashCode()相等,再看equals或==是否为false
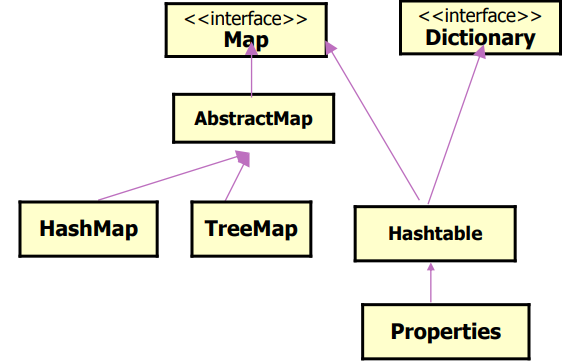
Map
• Map是键-值对的集合
其中可以取到entrySet()、keySet()、values()、
Map.Entry是一个嵌套接口
• Map类的重要实现
HashMap类
TreeMap类:用红黑树的算法
Map层次结构
系统已有的排序与查找
Arrays类及Collections类
Arrays类
• Arrays类是用于对数组进行排序和搜索的类。
Arrays.asList( 10, 7, 6, 5, 9) 方法可以直接得到一个List对象
• Arrays类提供了sort()和binarySearch()
• 执行binarySearch()之前应调用sort()
public static void sort(List list);
public static void sort(List list, Comparator c);
public static int binarySearch(List list, Object key);
public static int binarySearch(List list, Object key, Comparator c);
Collections类
此类完全由在 collection 上进行操作静态方法组成.
• 如sort, binarySearch, reverse等
关于比较
1.对象是java.lang.Comparable
• 实现方法
• public int compareTo(Object obj){
return this.price – ((Book)obj).price;}
2.提供一个java.lang. Comparator
• 实现方法 public int compare(T o1, T o2)
• 这些方法的含义要与equals不冲突
更多的排序与查找方法,如冒泡排序 、选择排序 、快速排序等,和二叉树、红黑树,Dijkstra算法的相关知识将来在算法和数据结构相关的文章中详细介绍。
